Crafter
About
Open world survival game for evaluating a wide range of agent abilities within a single environment. This project attempts solving part of the challenge of Crafter using Reinforcement Learning.
This folder contains the following code:
train.pyA basic training loop with a different types of agents. Feel free to modify it at will.src/crafter_wrapper.pyA wrapper over theCrafterenvironment that provides basic logging and observation preprocessing.analysis/plot_stats.pyA simple script for plotting the stats of your agent.analysis/plot_comp.pyA simple script for ploting the stats of all the agents as a comparison.analysis/plot_duel.pyA simple script that plots the attention of the duel agent on a game.analysis/plot_game.pyA simple script that plots stats of the games saved during eval.
Usage
Instructions
Follow the installation instructions in the Crafter
repository. It’s ideal to use some kind of
virtual env, my personal favourite is miniconda, although installation should
work with the system’s python as well.
Example using venv
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
For running the Random Agent execute:
python train.py --steps 10_000 --eval-interval 2500
You can specify other types of agents using --agent. Implemented random,
dqn, ddqn.
This will run the Random Agent for 10_000 steps and evaluate it every 2500
steps for 20 episodes. The results with be written in logdir/random_agent/0,
where 0 indicates the run.
For executing multiple runs in parallel you could do:
for i in $(seq 1 4); do python train.py --steps 250_000 --eval-interval 25_000 & done
You can also run other types of agents:
- random (default) Random agent
- dqn DQN Agent
- ddqn Double DQN Agent
- duel (modifier) Use duel NN architecture with DQN or DDQN Agents
- ext/eext (modifier) Use extra dataset recorded by the pro gamer himself with constant epsilon (ext) or with epsilon decay (eext)
- noop (modifier) Use the env modifier for training which substracts 0.1 from the reward for noops
- move (modifier) Use the env modifier for training that adds 0.025 reward if the action took is move
- do (modifier) Same as move and noop but add 0.025 reward if action took is do
- brain (modifier) Similar to move, noop and do. It adds extra reward if action took makes sense For example if player has 2 wood and places a table it gains 2 reward if the player has 4 stone and places a furnace it gains 2 reward for placing a stone it gains 1 reward for placing a plant in gains 2 reward. these rewards are awarded only for the first time
- valid (modifier) Check if the action taken by the agent is valid, if not substract 0.1 from reward that lil B has to learn the hard way that crafting iron picks is not the way to go in wood age
Modifier means that it can be used as a decorator: ext_duel_ddqn
python train.py --steps 10_000 --eval-interval 2500 --agent dqn
Visualization
Finally, you can visualize the stats of the agent across the four runs using:
python analysis/plot_stats.py --logdir logdir/random_agent
You can also visualize the stats of all agents using:
python analysis/plot_comp.py --logdir logdir
For other performance metrics see the plotting scripts in the original Crafter repo.
Results
Playing the game manually I have observed that the main difficulty comes from dying of starvation. The game becomes really difficult during the night when there are a lot of enemies. To be able to survive longer you need to create a zone that is separated from the outside world using stones, but this will make you run out of food. Something that I was not able to discover is how to use plants to get food.
The random agent manages to at best place a table and score around 2 or 3 achievements and it has an average return less than 2. The agent that manages to beat the random agent is the eext_duel_ddqn agent.
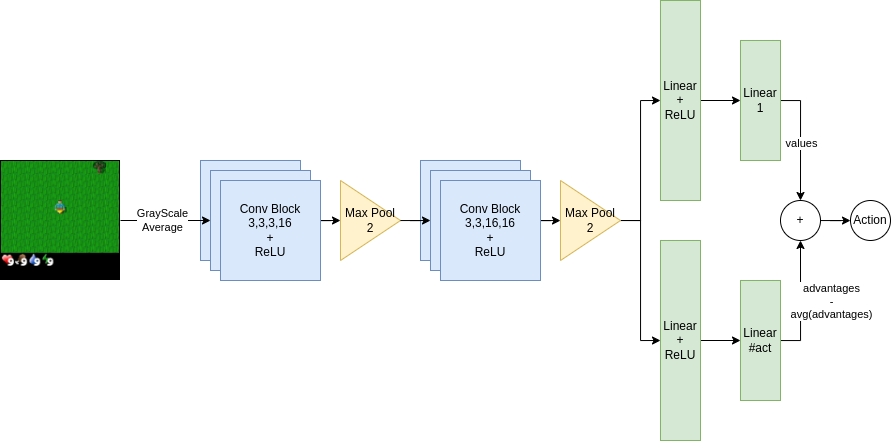
The input to the model is the grayscale image of the game. It uses the duel architecture described in the duel dqn paper. The model outputs the q values associated with each action. The agent will choose the action with the maximum q value during evaluation.
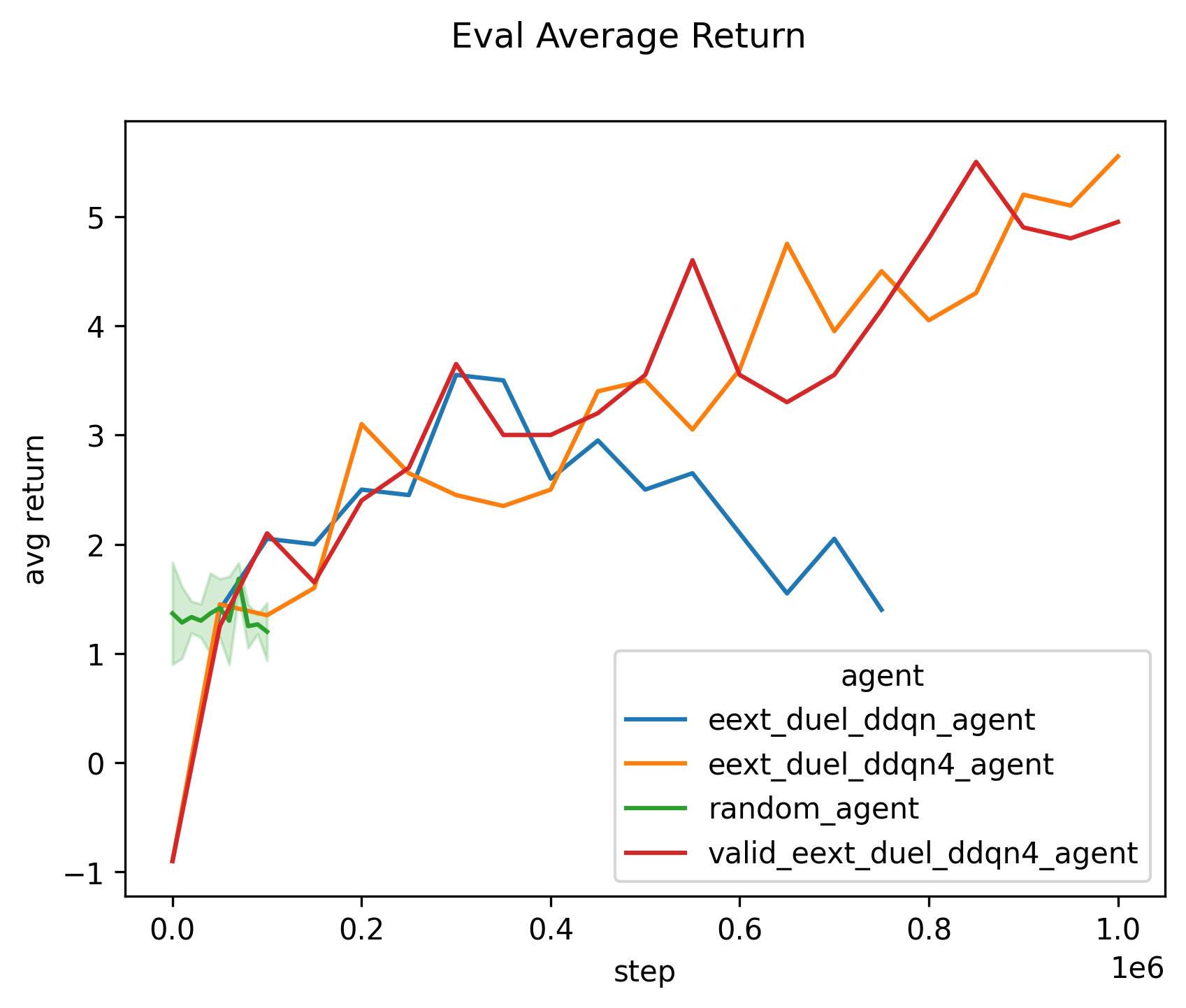
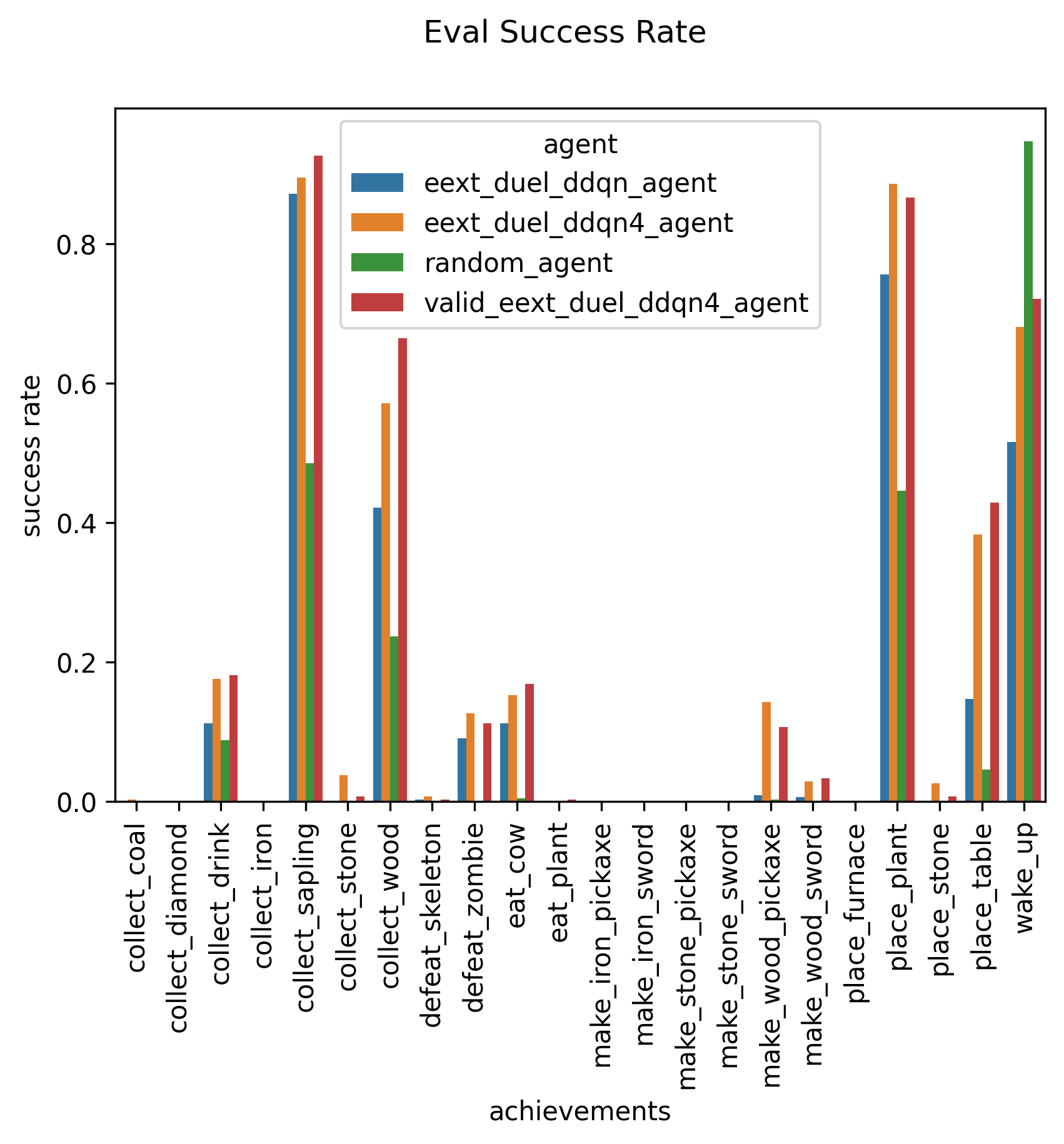
Tasks
- More visualization
- Episodic Reward for eval
- Loss plot for training
- Success rate for each achievement
- Distribution of actions taken with respect to time (step)
- Compare the methods (reward, success rates)
- Maybe try to create a plot like in the duel dqn paper? (saving the model, need to output the last layers and convert them to img)
- More algorithms
- DQN
- DDQN
- Dueling DQN
- Maybe try to penalize noop
- Explore intrinsic reward for exploring new states
- Give extra reward for placing table and stuff for first time.
- Stole an idea from some colleagues and made the random actions be actions that actually do something
- Test with penalize action that is not in the list of actions that do something (i.e the agent chooses craft iron pick but you have no iron)
- Test dropout in dnn
- (idk) Test with penalize same action multiple times in a row (or have like a diminishing return for actions) if the agent just spams space then he is bad and is a skill issue.
- More data
- Find a dataset with prerecorded good gameplay
- Record some gameplay using
python3 -m crafter.run_gui --record logdir/human_agent/0/eval - Create a replay buffer that randomly samples from prerecorded dataset
- More test runs to generate better plots
- 3 Runs with Random
- 3 Runs with DQN
- 3 Runs with DDQN
- 3 Runs with Duel DQN/DDQN depend on which will be better I guess
- 3 Runs with extended replay buffer (from human)
- 3 Runs with extended epsilon decay replay buffer (from human)
- 3 Runs with noop is bad environment and all modifiers YEET